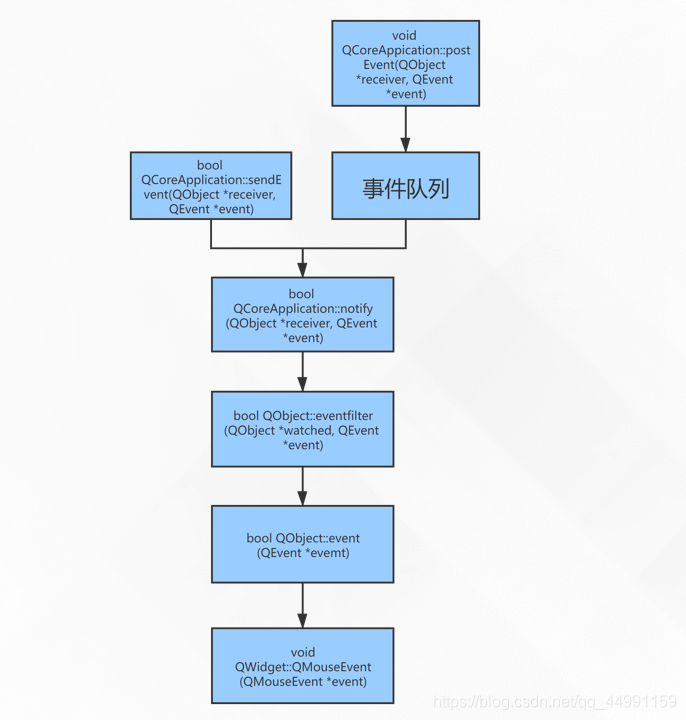
通义千问大模型微调
在之前的文章中,我分享了一些使用大语言模型开发应用的方法,也介绍了几个开源大语言模型的部署方式,
有同学给我留言说想知道怎么训练自己的大语言模型,让它更贴合自己的业务场景。完整的大语言模型训练成本比较高昂,不是我们业余玩家能搞的,如果我们只是想在某个业务场景或者垂直的方面加强大模型的能力,可以进行微调训练。
本文就来介绍一种大语言模型微调的方法,使用的工具是我最近在用的 Text Generation WebUI,它提供了一个训练LoRA的功能。
LoRA是什么
LoRA之于大语言模型,就像设计模式中的装饰器模式:装饰器模式允许向一个对象添加新的功能,而不改变其结构。具体来说,装饰器模式会创建一个装饰类,用来包装原有的类,并在保持原有类方法签名完整性的前提下,提供额外的功能。
LoRA,全称为Low-Rank Adaptation,是一种微调大型语言模型的技术。LoRA通过向大型语言模型添加一层额外的、低秩的可训练权重,来增强或调整模型的功能,而不需要改变原有模型的结构或重新训练整个模型。这就像是用装饰器包装了一个对象,增强了其功能,但没有改变原有对象的本质。
LoRA的关键思想是在模型的某些部分(通常是Transfomer注意力机制的权重矩阵)中引入低秩矩阵(低秩就是矩阵的行和列相对大模型的矩阵比较少)。在前向传播和反向传播过程中,这些低秩矩阵与大模型的权重矩阵相结合,从而实现对模型的微调。
相比完整的训练,LoRA训练具备两个明显的优势:
- 高效:微调过程中需要的计算资源和存储空间相对很少,如果训练数据只是几千条对话数据,我们可以在分钟级的时间内完成微调。
- 灵活:因为引入的参数数量相对较少,可以在一定程度上避免过拟合问题,使得模型更容易适应新任务。
因此,研究人员和开发者使用LoRA,可以在不牺牲模型性能的前提下,以较低的成本对模型进行有效的定制和优化。
工具安装
Text Generation WebUI 是一个开源项目,提供了一个Web界面方便大家做模型的推理和训练,大家可以在Github上下载到这个程序:
https://github.com/oobabooga/text-generation-webui
安装比较简单,如果遇到问题,欢迎留言讨论。
为了方便测试,我在云环境也创建了一个镜像,相关的环境都配置好了,可以直接使用几个国内开源的大语言模型,比如清华智谱的ChatGLM3-6B、零一万物的Yi-34B,还有最近阿里云开源的Qwen1.5-32B。
镜像使用方法:
1、访问AutoDL(https://www.autodl.com),注册个账号,充上几个米,金额要大于所租用服务器的小时单价。
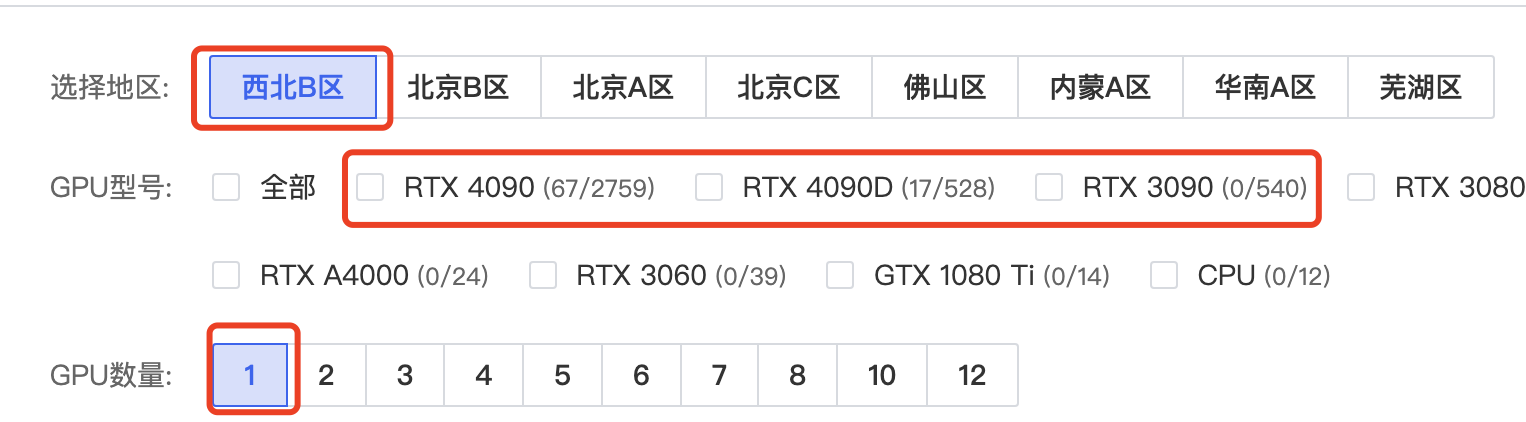
2、GPU型号:最好选择 3090 或者 4090。因为大模型需要的显存一般都不低,6B、7B的模型做推理都需要15G左右的显存。GPU数量选择1个就够了。
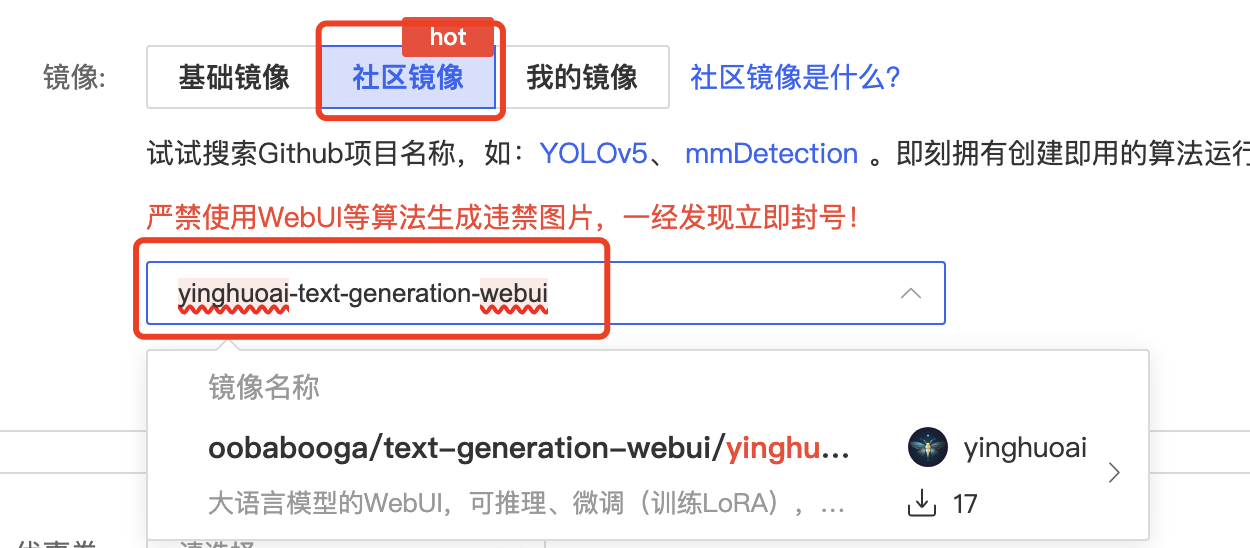
3、镜像:选择“社区镜像”,输入 yinghuoai-text-generation-webui ,即可选择到我分享的镜像。
4、服务器开机后,点击“JupyterLab”进入一个可编程的Web交互环境。

5、镜像内置了一个“启动器”,点击其中的启动按钮可以直接启动WebUI。

程序默认加载的是阿里开源的 Qwen1.5-7B-Chat 模型,你也可以更换别的模型,只需要去掉命令前边的“#”,注意同时只能加载一个模型,其它模型不使用时,请使用“#”注释掉。
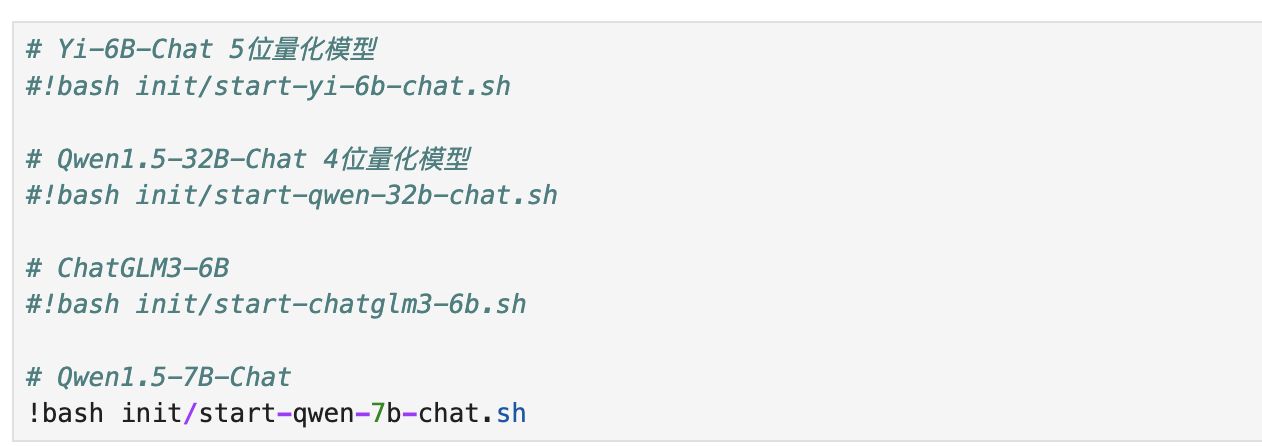
6、在下方的日志中看到类似输出的时候,就代表启动成功了。其中的 https://xxx.gradio.live 就是WebUI的链接,点击就可以在浏览器打开它的使用界面。

Lora训练方法
终于来到重点环节了。
训练
训练需要一个基础模型,镜像默认加载的是 Qwen1.5-7B-Chat。你也可以在WebUI中更换别的模型(前提是已经下载到模型目录),在 Model 页签这里选择别的模型,然后点击 Load 加载它。
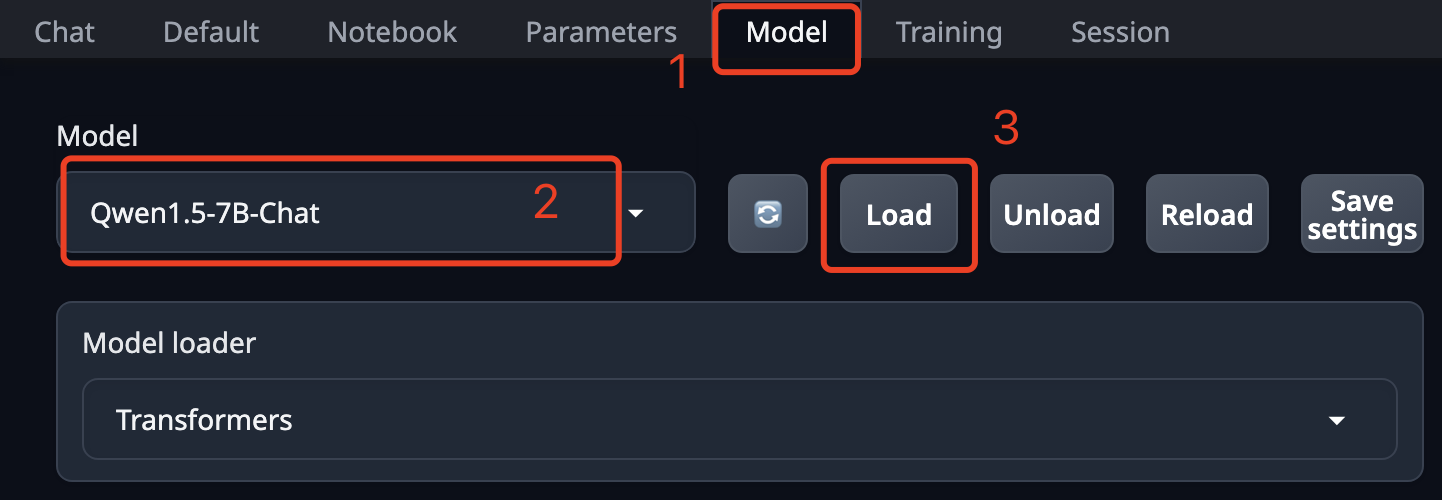
我们先来快速的过一遍训练过程,请按照下边的步骤开启LoRA训练:
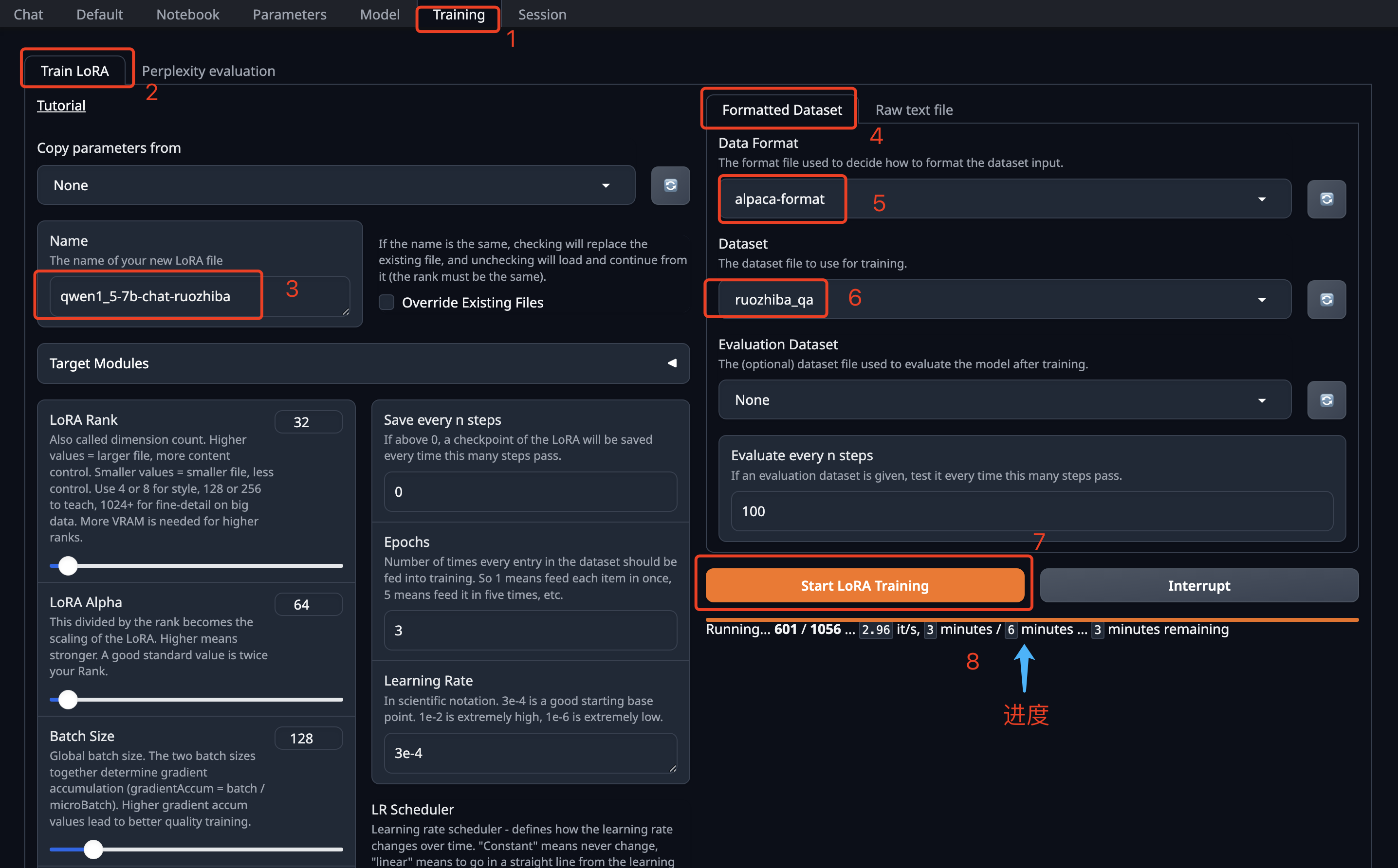
1、切换到 Training 页签。
2、点击 Train LoRA,进入LoRA训练设置页面。
3、填写Lora模型的名字,注意名字中不能包含英文的点(.)。
4、点击 Formatted DataSet,代表训练将使用格式化的数据集。
5、Data Format 数据格式,这里选择 alpaca-format,这是一种Json数据格式,每条数据声明了指令、输入和输出(其中input是可选的,我们可以把input的内容填写到instructions中,从而去掉input节点),如下所示:
{
"instruction": "下面是一个对话:",
"input":"只剩一个心脏了还能活吗?",
"output": "能,人本来就只有一个心脏。"
}
6、Dataset 选择数据集,我这里从 huggingface 上下载了一份弱智吧的问答数据集,镜像中已经内置。你如果使用自己的训练数据集,请上传到 text-generation-webui/training/datasets 中,然后在这里刷新后就可以选择到。
7、点击 Start LoRA Training 开始训练。
8、这里会展示训练的进度,还剩多长时间。
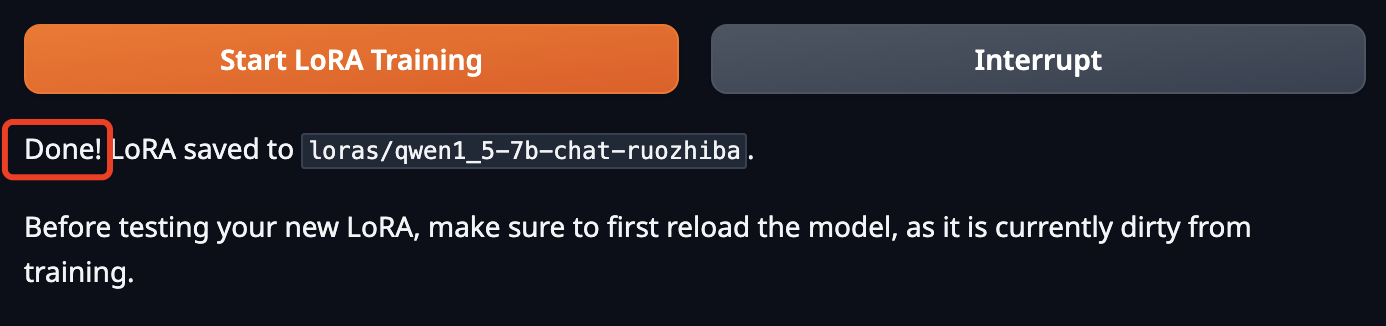
训练完成后,这里会显示“Done”。注意这里有个问题:如果WebUI和服务器断开了网络连接,这里就不更新进度了,此时可以去 AutoDL的 jupyterlab 或者你的命令界面中查看训练进度。
验证
训练完成后,我们需要测试下效果,参考如下步骤:
1、切换到 Model 页面。
2、点击 Reload 重新加载模型,因为此时模型已经被训练污染了。
3、刷新LoRA列表。
4、选择我们训练出来的模型。
5、Apply LoRAs 应用LoRA模型。

然后在 Parameters 中选择内置的聊天对话角色。
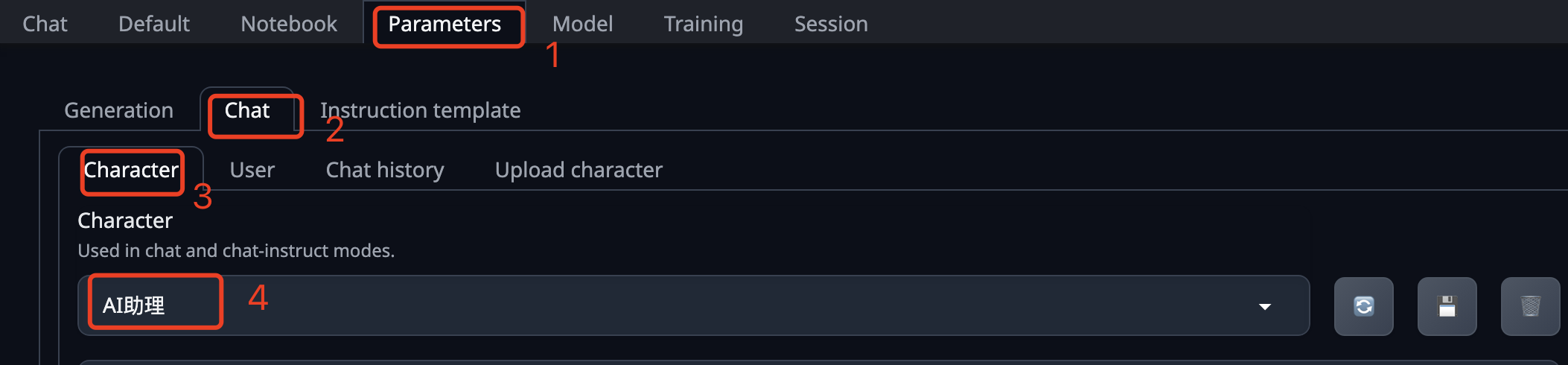
最后切换到 Chat 页面,开始对话测试。下面是我分别使用基础模型和添加LoRA模型后的对话截图,测试不是很严谨,但也能看到比较明显的差别。
两个 Qwen1.5-7B-Chat 很难回答正确的问题:
- 生鱼片是死鱼片吗?
- 小明的爸爸妈妈为什么不邀请小明参加他们的婚礼?


训练参数
在上边的步骤中我们使用的都是默认的训练参数,一般也就够了。但有时候对训练出的生成效果不太满意,就可以手动调整下训练参数,重新训练。
我这里把主要的几个参数介绍下:
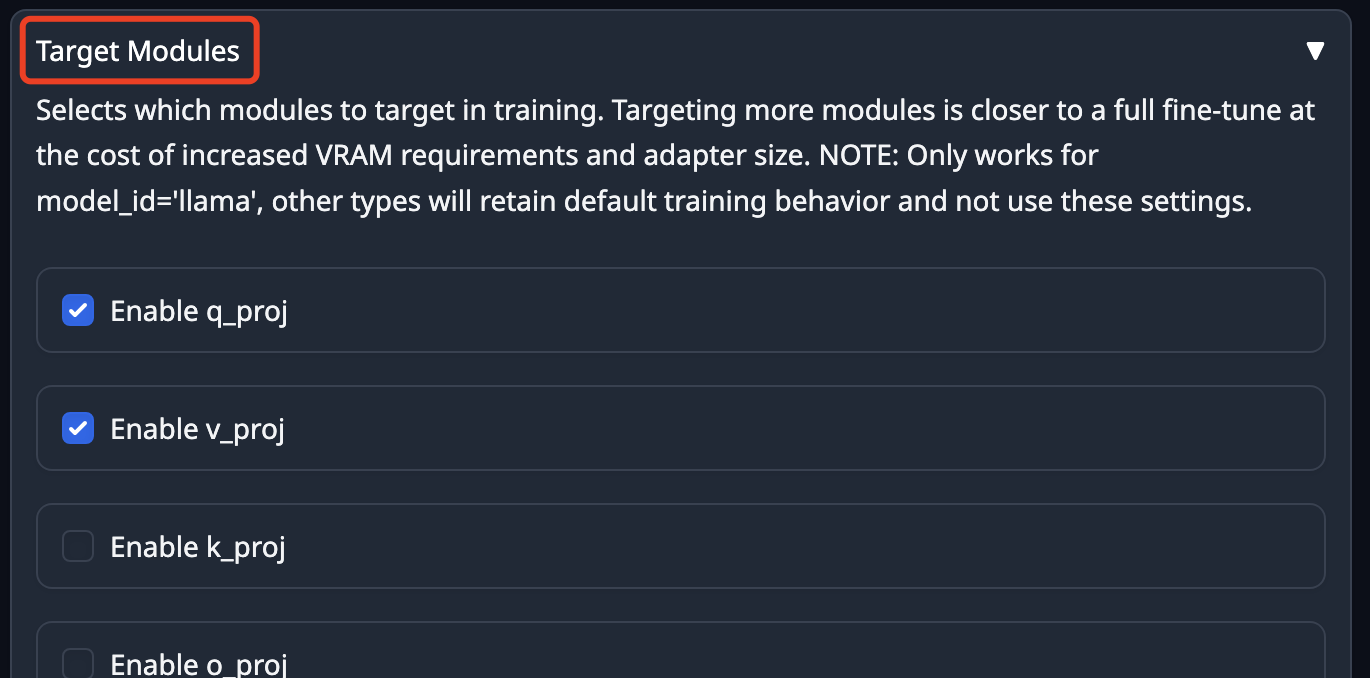
1、目标模块
这个参数仅针对 llama 类型的模型结构,默认勾选的是 q_proj 和 v_proj,具体的名词不容易理解,我就不多说了,可以简单的认为是对模型的理解能力进行优化,一般这两个就够了。当然我们可以勾选更多的项目,优化模型的生成效果。但是可能会导致两个问题,一是训练要使用更多的资源,更慢;二是可能导致过拟合问题,也就是只在训练的数据上表现的好,面对新问题就不灵了。Qwen1.5-7B的模型结构也是llama类型的。
2、Epochs
这个参数代表我们要训练多少轮。训练的轮次越多,模型从训练数据中学到的越多,生成就越精确,不过也可能会导致过拟合的问题,所以需要根据实际测试的结果进行调整。
3、LoRA Rank
维度计数,模型权重的更新量。值越大越文件越大,内容控制力更强;较低的值则表示文件更小,控制程度较低。
对于较为简单的任务或者数据量较小的应用场景,可以选择较低的值,比如4或8。这样可以保持模型的简洁性,减少所需的存储空间和计算资源,同时避免过拟合。
对于复杂的自然语言处理任务,特别是需要捕捉精细语义关系、句法结构或领域专业知识的任务,或者大规模训练数据时,可能需要选择较高的值,如128、256甚至1024以上,这样才有足够的容量来学习到复杂的模式。更高的LoRA Rank需要更多的显存支持。
LoRA Rank还应该与LLM的基础模型规模相匹配,百亿权重的模型可以设置更大值,因为它可以承受更多的权重调整而不会过拟合。
4、LoRA Alpha
数值越高代表LoRA的影响力越大,默认是LoRA Rank值的两倍。当这个值较高时,适应新任务的能力会增强,但是对基础模型的影响会比较大,有过拟合的风险,尤其是在数据量有限的情况下。当这个值比较低时,对基础模型参数的改变较为温和,这可以保持预训练模型的泛化能力,但也会降低对新任务的适应性,特别是LoRA任务与预训练任务差异比较大时。
5、Learning Rate
学习率。机器学习在训练过程中会不断检查自己与训练数据的偏离程度,它有个名词叫损失(loss),一个合适的学习率会让损失逐渐收敛在一个最小值。如果学习率太大,步子就会迈的太大,不能获取较好的效果;但是如果学习率太小,又会训练的很慢,成本太高。如下图所示:
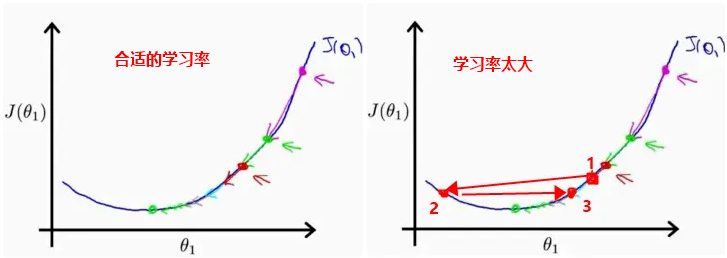
默认值 3e-4 表示 3 乘以 10 的负 4 次方,也就是 0.0003。最大1e-2表示0.01,最小1e-6表示0.000001。
另外需要平衡学习率和轮次:
高学习率 + 低轮次 = 非常快但质量较低的训练。
低学习率 + 高轮次 = 较慢但质量较高的训练。
6、LR Scheduler
学习率调度算法,默认的是线性衰减,也就是随着学习轮次的增加学习率逐渐降低。
还有使用常量、余弦退火、逆平方根、多项式时间等算法,线性衰减和余弦退火比较简单有效,平常使用的比较多,逆平方根衰减和多项式时间衰减在处理大规模数据或需要长时间训练时能提供更为稳定的收敛表现。
一个好的模型与训练数据和训练参数都有很大的关系,很难一蹴而就。
如果你对训练的结果不满意,可以调整这几个参数试试。注意重新训练前,先把基础模型重新加载。
以上就是本文的主要内容,如有问题,欢迎给我留言交流。




![pwn--realloc [CISCN 2019东南]PWN5](https://img-blog.csdnimg.cn/direct/c63f2dba8fc7469ebc4ec33f46f57fa7.png)